


图数据库市场近年来爆发式增长,其中一个核心的原因是,图数据库相较于关系型数据库和以Hadoop为代表的NoSQL数据库,数据建模的方式产生了根本性的变化。我们都知道,schema的设计不是一个一蹴而就的过程,而是随着对于数据和业务需求不断变化演化的过程。图数据库相较于其他类型的数据库,schema的调节更灵活影响更小,大家不用过分纠结于在一开始就做出完美的schema,也可以避免过度设计等工程陷阱。我们将会把设计图schema的一些常识和对于TigerGraph来说性能较优的设计思路分享给大家。
本期随身听我们邀请到了 TigerGrph客户成功团队的工程师林选磊为大家解读《图数据库建模最佳实践》,今天的内容是满满的干货,为了方便大家更好地理解本期内容,我们在正文中添加了图示,可以搭配图文一起收听。下面我们开始今天的随身听。我们知道,家庭物品收纳整理有个重要的原则,就是分类。人们不会把所有的衣物乱堆在一起,而会按衣服的用途、颜色等等进行分类,这样衣物才会井然有序,容易取用。
类似的,现代企业的数据容量爆发式增长,如果没有数据模型,数据就会杂乱无章。人们需要对数据按业务概念进行抽象和归类,设计数据结构,让数据各归其位,这就是数据建模的过程。数据建模影响重大,因为它是业务与技术之间的桥梁。企业从数据库的建立之初,到日常的数据分析,无时无刻不与数据模型打交道。
当业务人员对日常数据进行分析时,当决策层依据数据做决策时,必须要将业务语言依据数据模型转化为查询,就是query。一个好的数据模型,能让数据分析人员容易理解,也容易使用,并且解决日常的业务问题的时候,性能也是足够优秀、消耗的资源足够少。因此设计模型有比较强的查询用例导向性。
对于分析类的数据库来说,数据建模还要考量输入的数据的格式。因为我们要基于已有的数据,挖掘其中的信息,而不能脱离实际。数据建模最常用的方法,就是E-R图(E-R模型,也就是实体-关系模型),它在传统的关系型数据库中就已经非常流行,但其本质上是一种图的方法,也就是关系数据中有哪些实体,有哪些属性可以用来描述这些实体,实体与实体之间有哪些重要的关系,然后再将这些实体、关系和属性的类别进行抽象。
举个例子,学校里有很多学生、老师,也开了很多课堂,那么就可以把学生、老师和课堂抽象成三类实体。我们会发现,最容易抽象为实体的类型往往是一些名词。每个实体都有一些描述实体本身特征的属性,比如描述老师的姓名、性别、年龄等等,这在数据模型中称为属性。而实体与实体之间的关系,比如李同学参加了语文课,王老师教语文课,那么学生与课程之间的“参加”关系、老师与课程之间的“教”的关系,可以抽象成两类关系。因此关系经常会是一些动词。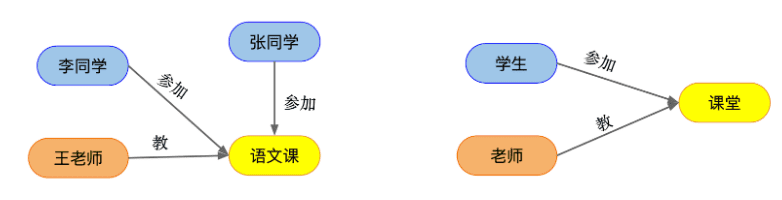
我们都知道,关系型数据库最终落地都是一张张独立的表,表与表之间的关联关系并不直接,它需要通过主外键才能够关联起来。所以很多新手数据分析师,有的时候都忘了他设计之初的那个E-R图。近十多年大数据的发展,虽然大大提升了对数据的存储和计算能力,但是深层的分析方法仍然没有脱离表的思维方式。而用表去表达图状的E-R模型,既不直观,又缺少灵活性,还牺牲了查询的性能和深度分析的能力。
直到出现了图数据库,我们看到它在设计上、使用上都高度重视关系,关系会直接传输到数据库里面,那么数据建模的时候,整个模型才能更加的符合这种E-R模型,也非常容易去反映业务概念,数据查询的表现能力、表达能力也发生了质的飞跃,以往觉得很难的查询在图里面表达起来直接而又非常高效。
那么在数据库中,我们常常会把模型称为schema。根据处理schema的方式不同,将数据库分为三大类:一类是schema优先,也就是说,它预先要定义一个schema,而且所有加载进去的数据都必须要符合这个schema。第二类是没有schema的模式,这种就是每个单独的实体都有独特的属性,并没有做统一的规范,这种建边的话是按需去建的。那还有第三类的就是混合模式,它是介于两者之间的,也就是schema可选。那么它是有一套schema,但是并不强制要求所有数据都要符合它的规范。
那么采用第一种方式,即schema优先的这种方式,其实是优点是最明显的。因为它能够很好的反映这些业务概念,又能够保证数据的一致性,还方便简化了查询,改善数据共享,权限控制,还可以提升查询性能。TigerGraph 就是schema优先型的这种数据库。
前面跟大家介绍了数据建模以及数据建模的重要性,那么下面我们再以 TigerGraph 为例,介绍一下图数据库建模的最佳实践。我们将涉及到九个主题,逐步跟大家介绍。


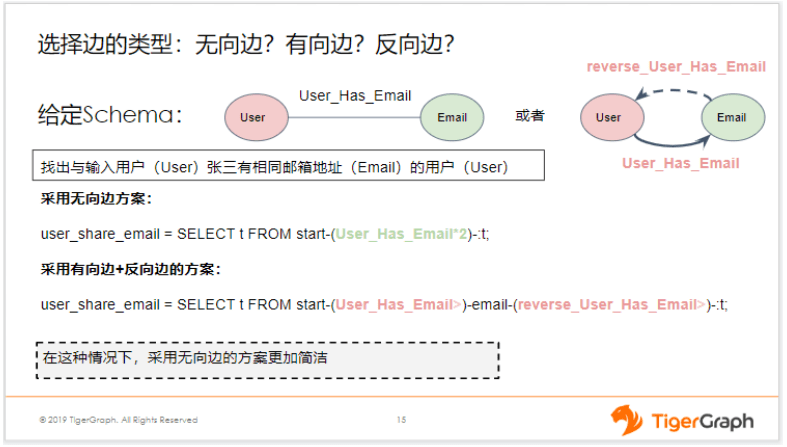
我们以这个用户使用邮件的案例为例,用户和邮件是两种顶点,如果采用方案一,即用一条无向边去表达他们的关系——用户拥有什么Email。而第二种方案,是用一条有向边+一条反向边去表示这种关系。那我们现在给定一个输入的用户,比如张三,我要查询与张三拥有相同Email的这些用户。那显然我们要2跳,第一跳,我要找到张三有哪些Email,第二跳,我们从这些Email出发,再找到对应的使用它们的用户。
如果我们用方案一,我们采取的这个GSQL就是上图中所示,通过使用User_Has_Email两次,即跳两次,相当于从User跳到Email,再跳回到User,这样就解决了。那如果是采用方案二,即有向边+反向边,我们就得写两个不同类型的边。先用User_Has_Email,再用reverse_User_Has_Email跳回到User上面。这两种方案对比,显然第一种采取无向边的这种方案更加简洁。尤其是当我们查询的跳数非常多的时候,这种优势就非常明显。比方说,我们有一个while循环,我要跳很多次,那采用方案一就更好些,它更加简洁。所以对于这种两头连接的顶点是不同类型的,这种情况还是比较推荐使用无向边。
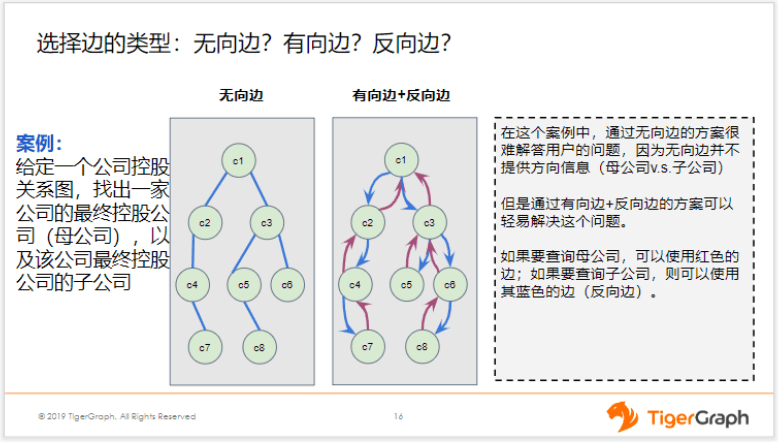
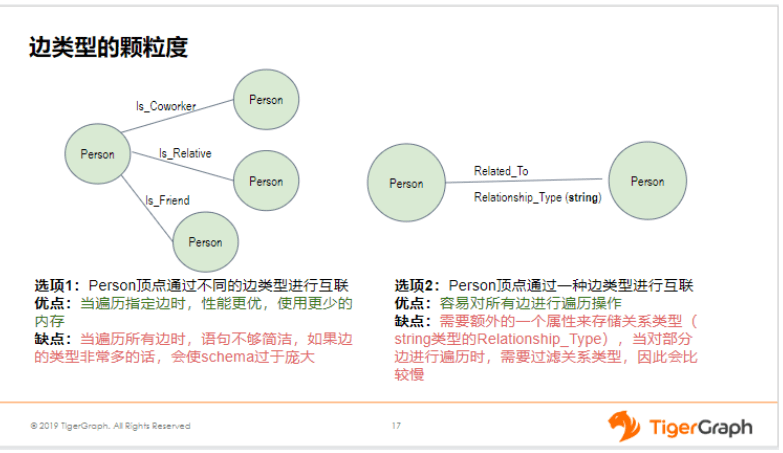
具体要选哪种方案,我们要看情况。前者的优点是,当我们只遍历一种类型的边时,比如我只查询朋友关系,那这种情况它的性能更优。但当遍历所有边时,它的语句不够简洁,尤其是当类型非常多时,比如你有100种类型的关系,那就可能会使schema变得非常非常庞大。那这种情况后者就更有优势。
一般来说,我们要考虑两个因素,一是边的类型到底有多少,二是我到底是对所有边进行查询的情况居多还是对单独的、个别类型的边进行查询的情况居多。
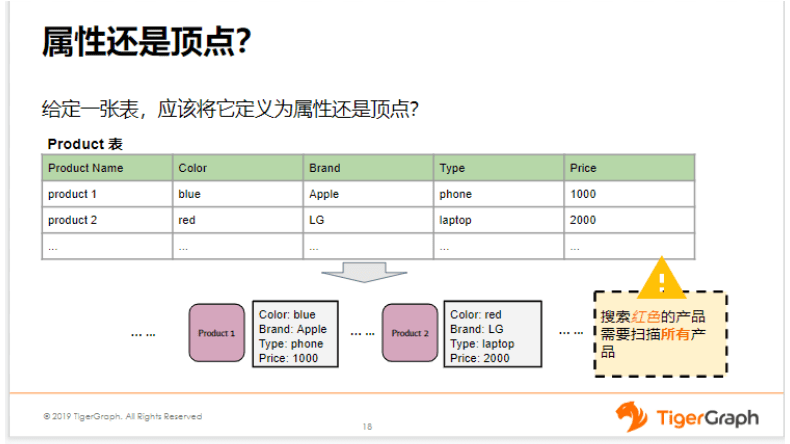
那么这个方案有什么缺点呢?假如我要从这里面搜索红色的产品,那么我就需要把所有的产品全部搜索一遍,从中过滤出那些红色的产品。这个方法相当于回到了我们传统关系型数据库的做法,即要对全表进行遍历才能得到我想要的数据。但它并不能体现图数据库的优势。
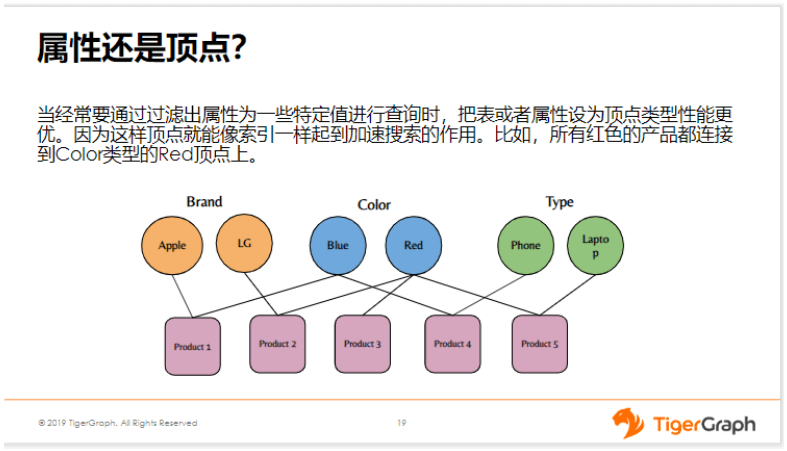
所以为了解决这个问题,我们可以采取第二种方案,也就是把其中经常用来过滤的这些属性,比如品牌、颜色、类型,我们把这些属性提炼出来,当做单独的顶点。然后下次我要查询红色的这些产品的时候,我们就可以从这个红色顶点出发,跳一跳,就可以查到所有跟它连着的产品。假如我们有一亿的产品,其中红色的产品可能只有100万,那么我们就只有100万条边,我只要遍历这100万条边就可以了。比起第一种方案的全量遍历,通过where条件进行筛选的方案,第二种方案明显要优很多,性能要好很多。
当然,在 TigerGraph 中我们还有更加简便的方案,也就是可以对这些属性直接添加索引,而无需把这些属性提炼出来作为顶点。这个功能早已在 TigerGraph 3.0中实现,大家可以结合自己实际的业务需求来探索使用。
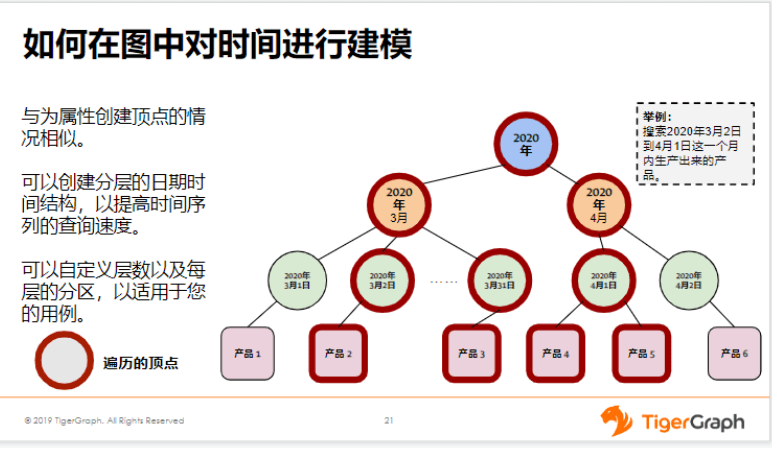
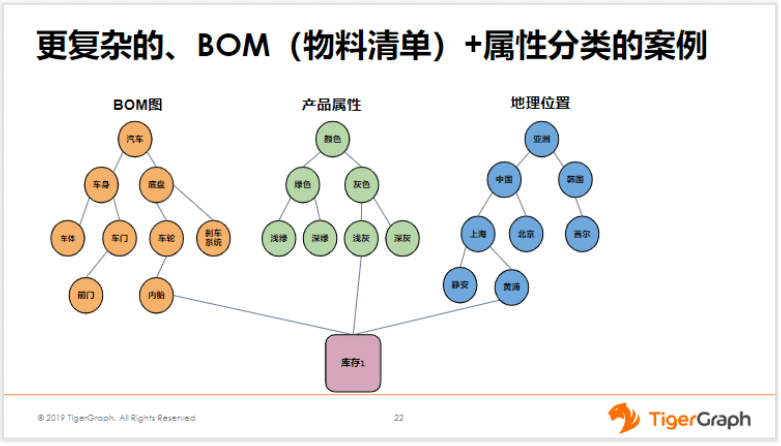
我们这个案例中,可以看到有BOM图、产品属性、地理位置,下面的库存就是在限定了上面这些条件以后,它的库存有多少。这个是库存的记录。可能你会问,假如我要符合三个条件——即同时符合内胎、又是浅灰色、又在黄浦区,那这样的库存有多少?这在TigerGraph中应该怎么实现?
其实很简单,我们首先以BOM作为起点,找到内胎所对应的库存,得到一个集合。然后再从浅灰跳一跳找到对应的库存的集合,然后再从黄浦跳一跳得到库存的一个集合。最后再取这三个集合的交集,就是同时符合三个条件的数据了。在TigerGraph中取交集其实非常简单,只要一行代码就可以解决,即通过Intersect就可以完成了。
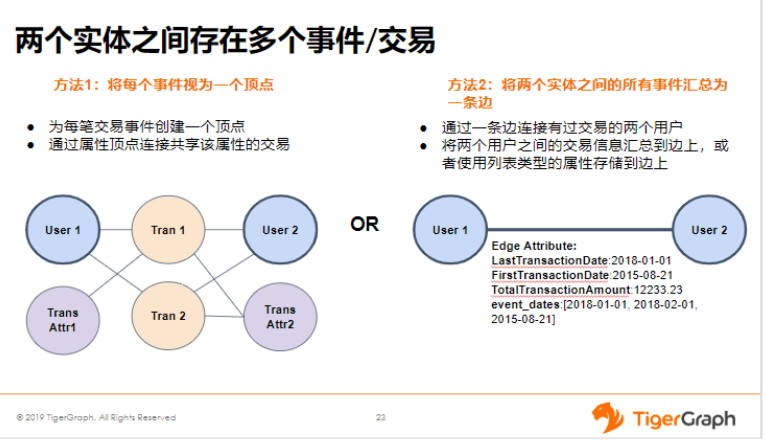
那左边的方案就是把交易定义为顶点,对于这种方案,我们就可以把交易上面的一些属性,比如TransAttr2,它们可能是交易1和交易2共用的、共享的一些属性,我们把它们提炼出来作为单独的顶点。通过这种方式建模,它的数据当然是很多的,因为到了交易层,数据量肯定是很大,但也是最详细的描述真实的一些交易的情况。
那第二种方案就是通过用户和用户直接连接,这种情况,交易的信息应该放哪里呢?我们放到边上面。但这里就很难存储那些很明细的数据,我们可能只能存一个汇总的数据,比如最早的交易时间、最晚的交易时间,以及交易的总金额等。如果想要往里面加一些明细数据,其实也是可以的,但是会比较绕一点,我们会向上面加一些list类型,即列表类型的属性,比如时间序列,把它存在边上。
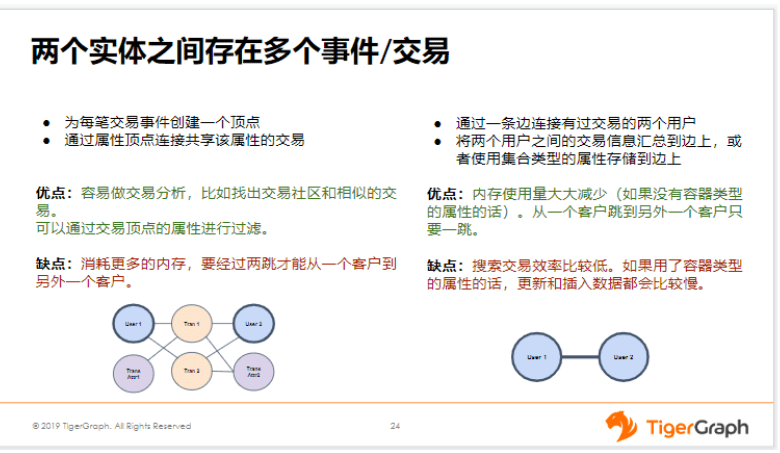
那这两种方案,其中第一种方案比较适合什么场景呢?这种比较适合分析交易,比如我想要查询某笔交易的明细,还可能要查它们之间的一些共用的属性等等,通过属性进行过滤等场景。但是当进行客户分析的时候,因为客户到客户的关系不是直接连的,所以客户到客户需要经过两跳。第一种方案就不太适合进行客户分析。
关于第二种方案,存储空间要少很多,并且客户到客户只有一跳,所以很适合进行客户反欺诈这种场景。但它的缺点是什么?就是搜索交易的效率太差了,尤其是如果你存了这个列表类型的话,其实它还有引申出另外一个问题就是,这种列表类型,当你做数据更新或者数据插入的时候,速度都会比较慢,这是它的另外一个问题。
那我们应该怎么选择呢?其实需要根据实际的场景来做决策。看我们到底是需要经常查询交易的数据,还是会做用户之间的网络分析。如果我们存储空间足够,那么把两种都存起来也是没问题的。
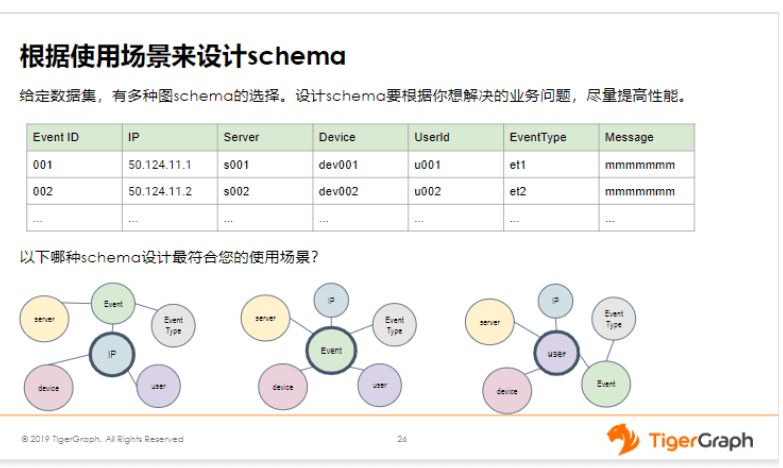
这个完全要依据我们的使用场景去做决策,比如像后面两种——以事件为中心和以用户为中心,这两种都是非常常见的设计方式。
像以事件为中心的这个方案,它的好处是什么呢?它就很适合查询那些事件的明细,进行围绕事件为中心的这种分析。第二种呢,就很适合查询那种以用户为中心的分析。比如给定一个用户,我要查找他在N跳之内的黑名单的用户有哪些?有多少个?再比如给定一批黑名单客户,我知道他们的模式是怎么样的,然后我要去其它的白名单客户中寻找那些跟他们的模式相似的这些客户。再比如,我们有可能检测两个用户之间的连通性,等等。那这些场景就很适合以用户为中心的这种设计方案,把其它结点都连到用户上面去。

Anna Veronika Dorogus
Machine Learning Expert
Anna Veronika Dorogush graduated from Lomonosov Moscow State University and Yandex School of Data Analysis. She used to work at ABBYY, Yandex, Microsoft and Google on Machine Learning infrastructure and Machine Learning frameworks. In 2017 she published the open-source library CatBoost, which is now one of top-3 most popular Gradient Boosting libraries, and the top 7-th most used Machine Learning framework in the world according to Kaggle 2021 review.