


各位专家,各位朋友大家好。我是联通数字科技有限公司的冯翰斌。首先特别感谢TigerGraph提供这样的机会,能够让做图应用的行业、企业共同分享和探索各自领域内图相关知识的探索与实践。在数字化转型的背景下,中国联通大数据业务也是得益于全国数据物理大集中的优势,率先探索市场化对外服务,也积累了一定的市场化要素配置的经验。因此,今天的内容也是基于公司的一些技术能力的实践为大家分享,主题是基于图的数据治理加速企业数字化转型。
下面我们就一起来看看如何在企业数字化转型的背景下,用图技术来助力数据治理。
我今天的分享主要分为两部分。第一部分主要是介绍公司的背景、已有业务以及大数据能力体系。第二部分,我会详细介绍图在数据治理的细分领域及血缘关系分析上的应用。其中包括数据加工链路中上下游影响分析,如何解决数据冗余存储、冗余计算等资源浪费的一系列问题。接下来,我们首先进入第一部分的内容。
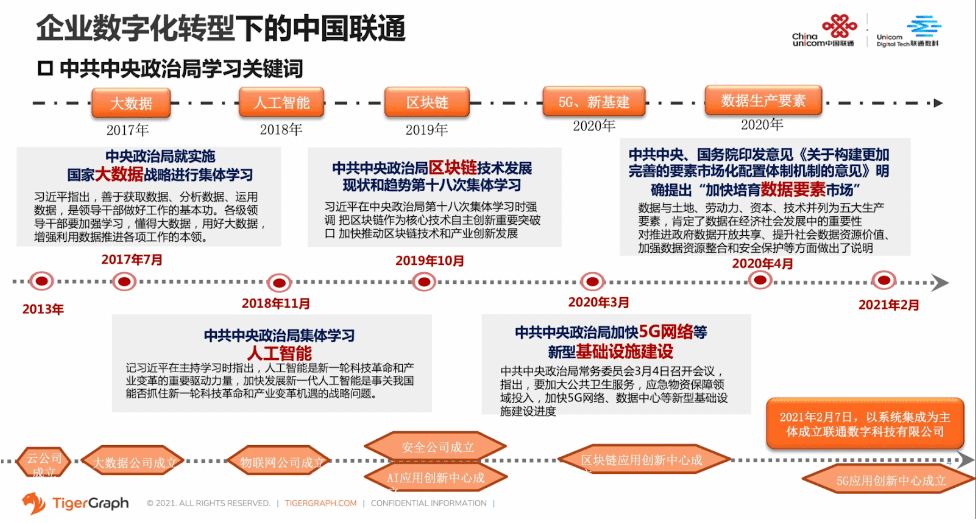
随着我们国家科学技术的快速发展,数字化,也被认为是提升现代化水平的基础。不论是1964年提出的工业、农业、交通运输业和国防现代化,或是十八大提出的中国特色新型工业化、信息化、城镇化、农业现代化,十八届三中全会提出的国家治理现代化,还是我们现在常说的大数据、人工智能、区块链、5G等等,都需要以数字化作为基础。因此,党中央也是高度重视。我们可以看到,从17年开始,先是中央政治局就实施国家大数据战略进行集中学习,再到19年习近平总书记在G20大阪峰会上,就对数字经济特别会议上作出的指示,都强调了数字化的重要性。所以说,企业数字化的转型势在必行。
那么在这样的大背景下,中国联通在这方面也是在不断的探索数字化体系的建设。对内,加快推进全面数字化转型。对外,以人工智能、大数据、物联网、互联网、区块链、5G技术为基础赋能,致力于成为政企客户数字化转型的赋能者。
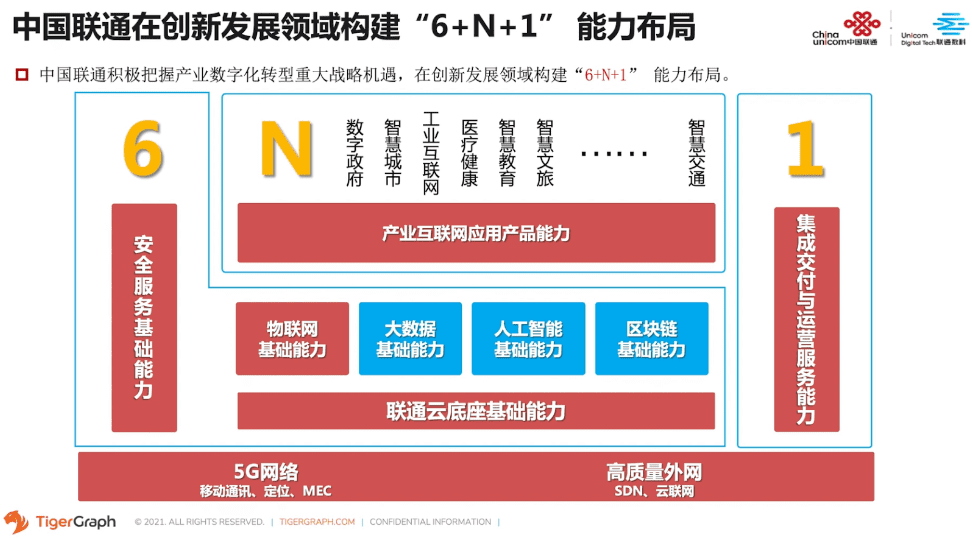
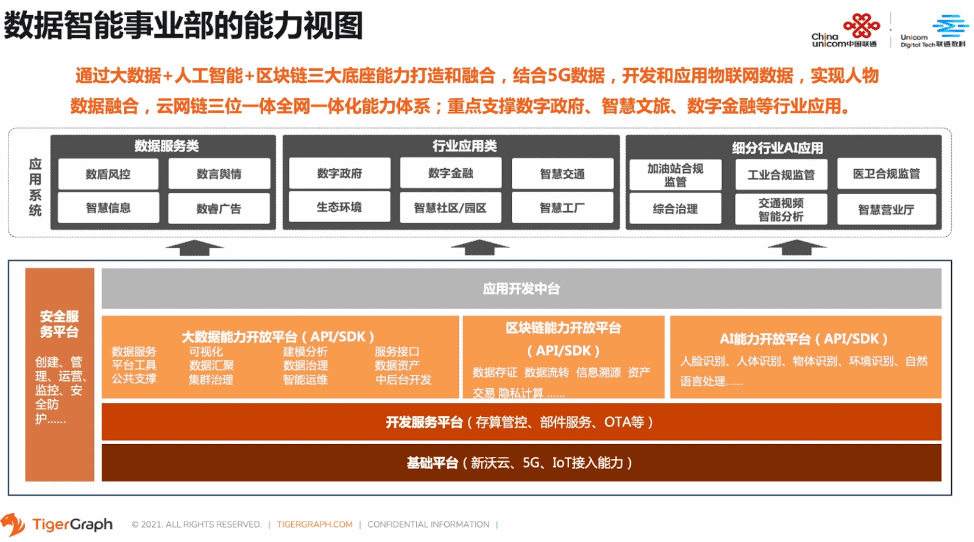
同时,我们中国联通也承担了政企BG 6+N+1创新业务能力体系中大数据、人工智能、区块链的能力建设。通过大数据+人工智能+区块链三大能力底座的打造和融合,结合了5G数据、开发和应用物联网数据,实现人物数据融合,云网链三位一体化能力体系,重点支撑数字政府、智慧文旅、数字金融等行业应用。
那么对于我们联通数字科技有限公司,数据智能事业部,是底层的数据保障部门。举几个例子,比如金融授信中的姓名、身份证、手机号、三要素核验、位置核验、旅游中景区人群流量监测与监控,那么还有在洞察场景中的门店选址,联通数科提供适合多行业的通用产品和垂直行业平台产品及解决方案,并以数据服务、数据融合应用服务的产品模式,满足金融、政务、文旅、交通、公共安全等行业客户的细分要求。
这里,必须要提一点,联通数科公司坚持数据安全是生命线,安全事件零容忍,敏感数据不出门的三大安全原则。解读起来其实就是对数据具有完整性的安全管控体系。这里通过制度及手段对数据安全进行严格的把控,包括安全的分类、分级、加密、脱敏、安全网关审核等等,数据服务从需求层面就会做安全的审核。
下面也是我们中国联通在实际技术能力上的一些具体体现,主要从打造6+6大数据能力体系、依托数据科学平台、数据资产管理平台等六大平台支撑,为客户提供全面的大数据整体解决方案。
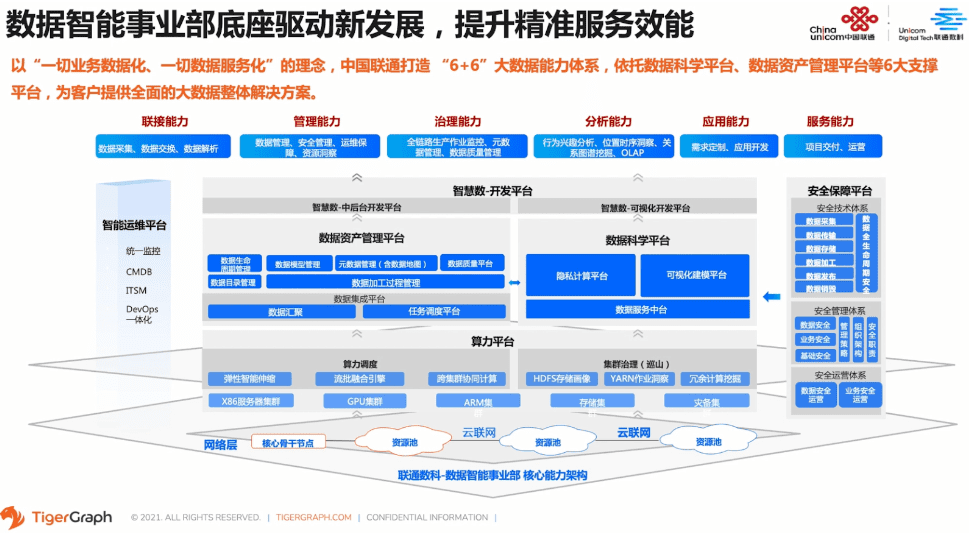
对此,我们事业部在公司整体算力平台和数据资产平台的共同加持下,把每天联通运营过程中产生的数据抽取出一些容易结构化且对行业有价值的数据,进行数据加工和保存。即使已经优中选优,目前的存量也将近100PB。目前数据的日增量是200多T。日运行加工的job,会达到上万,这里包括100多个库、7000多张表、200多个加工模型,依托在2000个节点的集群的运算规模上。数据维度上来看,主要包括脱敏的用户基础信息、通话、短信、语音、流量及关系数据、物联网日志与信令数据。在集团网联云算数字的逻辑层中,我们属于最上层。
那么,这么大的数据量和这么多的数据维度,基于数据安全,全链路生产、元数据管理、数据血缘分析和数据质量集合等数据治理能力必不可少。

联通数科数据智能事业部,在2018年集群规模就达到了数千节点,同时数据相关资产及业务迅速增长,数据仓库规模也在快速膨胀。而我们因为数据管理成本的增加,计算能力的下降,冗余存储、冗余计算等资源浪费的一系列问题,让我们数据环境一度处于失控状态,需要投入大量人力资源去保障数据环境的运行。
当时的问题我们归结为三类:数据管理类、集群算力类、监控洞察类。
那么,数据血缘分析也就是解决上述问题做且必须要做的重要的一环。
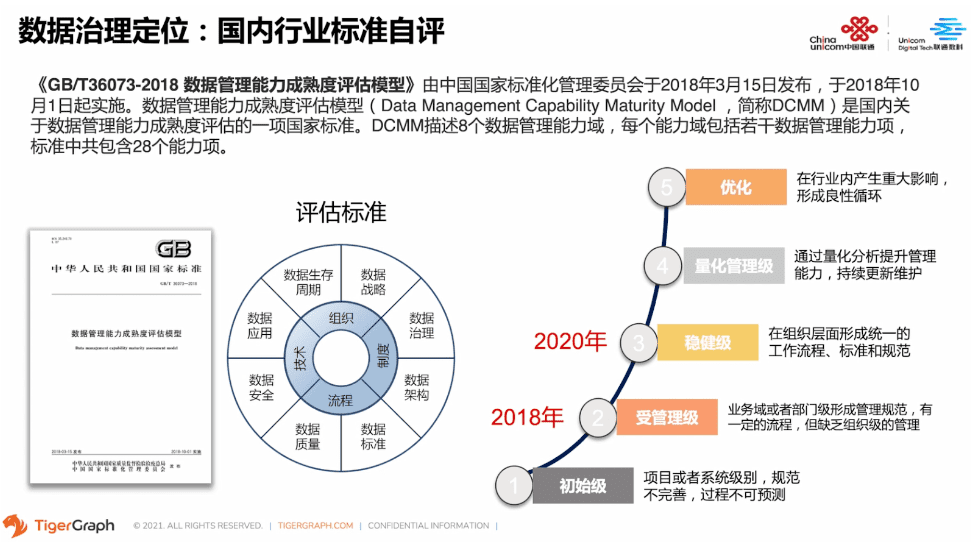
那说到数据治理这块,国外已有了像DAMA、CMMI、DCMM这样相对成熟的理论体系,里面包括很多的能力域、过程域、价值域的建设。在这里面,联通数科主要参考对标的是国家的DCMM标准,即数据管理能力成熟度评估模型。这是一套综合标准规范、管理方法论、模型评估等多方面内容的综合框架。模型覆盖8个数据管理能力域,28个数据管理能力项,5个成熟度等级。我们已经完成了DCMM成熟度的等级评估,达到了四级的标准。

数据血缘是数据治理的细分领域重要的应用功能,为我们的数据管理人员和数据开发人员提供了很大的帮助。通过数据血缘,我们可以做到跨数据源、跨存储,对数据源进行全链路的跟踪影响分析。数据孤岛的洞察,让数据加工流程可以追溯,数据敏感流向可以跟踪,数据影响范围也可以快速地评估。通过数据血缘的应用,最终我们期望达到的目标是以无侵入的方式完善企业级全域的数据管理平台体系,提供全域物理视图、业务视图、元数据变更跟踪监控、全域数据血缘关系图等核心功能。
那我们有了明确的目标导向,也依托于TigerGraph图数据库强大的计算引擎,帮我们完成了数据血缘中关键的一环。我们的数据血缘系统建成后,也就自然具备了几个特点:
下面我们就来看一下我们在数据血缘系统构建的工作上都做出了哪些努力。
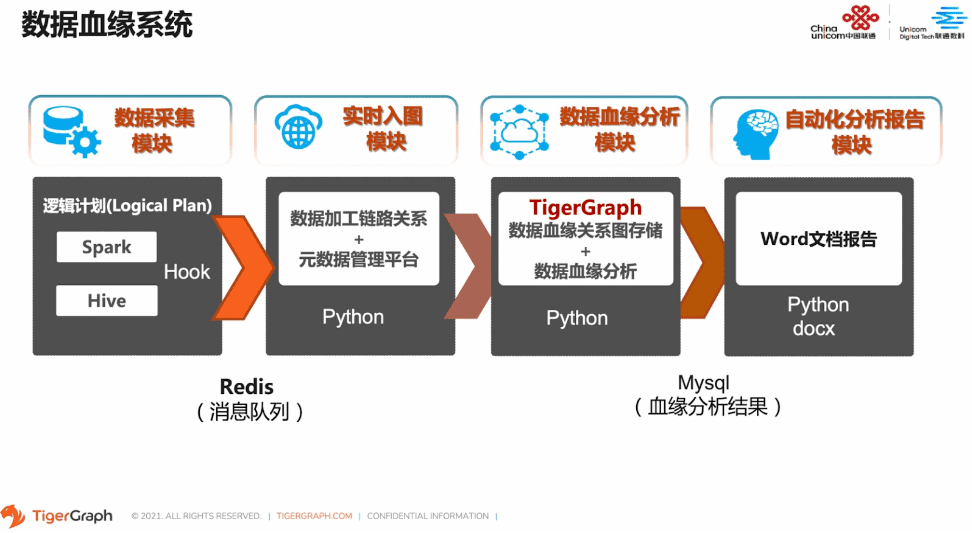
我们的数据血缘系统,主要包括以下四个模块:数据采集模块、实时入图模块、数据血缘分析模块和自动化分析报告模块。
虽然数据采集也是数据血缘中非常重要的部分,而我们在采集Spark的加工流程时也遇到了很多困难,但是这并不是我们今天分析的重点。那接下来我们就着重看一下后两个模块——图计算在血缘分析中的应用。
下面介绍一下血缘分析模块中的图计算存储部分。
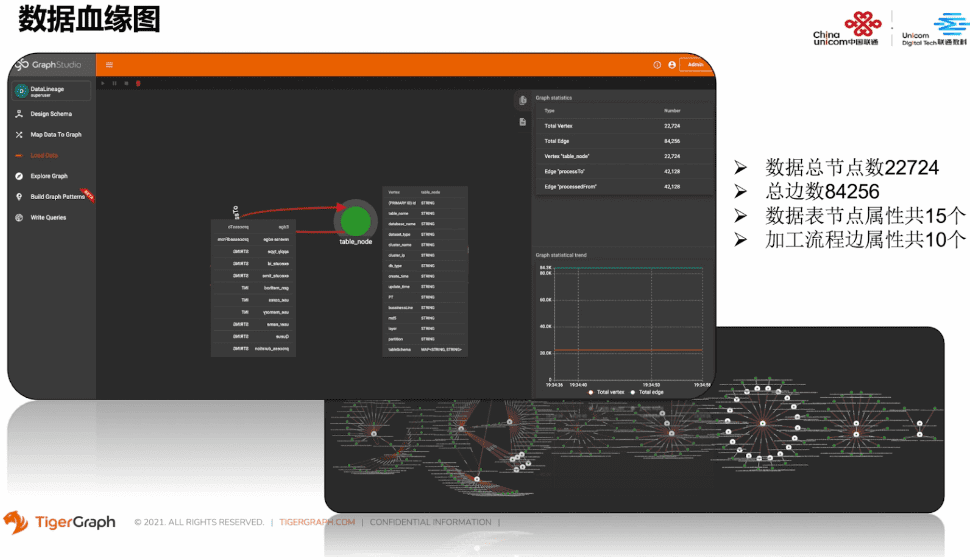
图数据库存储的就是数据表加工链中关系图构建的血缘关系图。其中,节点类型就是数据表,包含的属性有:数据表的基本信息、业务线、数据表、储存层级、Schema等。边的类型为加工流程指向。边属性包括操作类型、执行ID、执行时间、数据表产生方式、占用资源、队列名、执行时长等。目前,图内数据的总结点数是22,724个,边的总数是84,256个,数据表的节点属性共15个,加工流程边的属性共有10个。
刚才讲的是数据血缘分析中图数据存储的内容,那下面我们来看一下整个血缘关系系统最核心的部分——血缘分析。
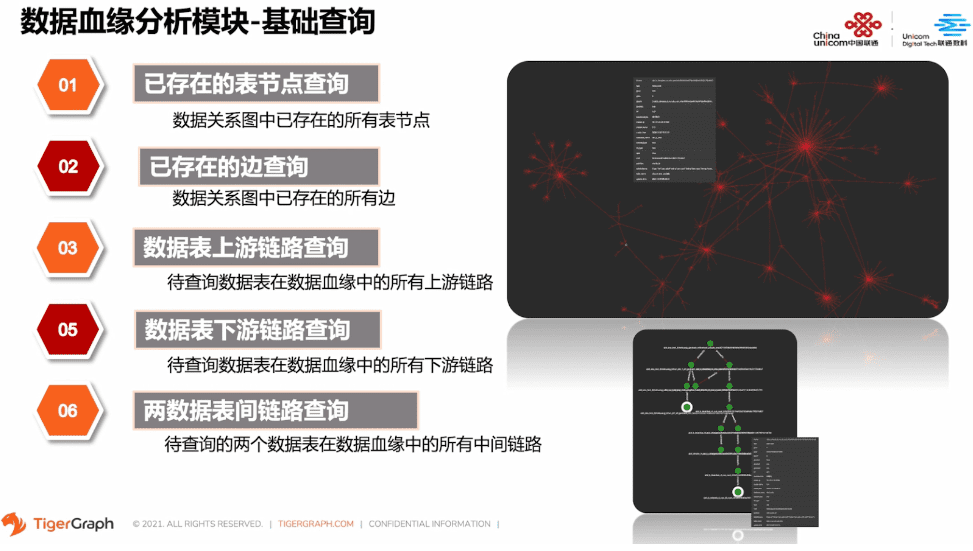
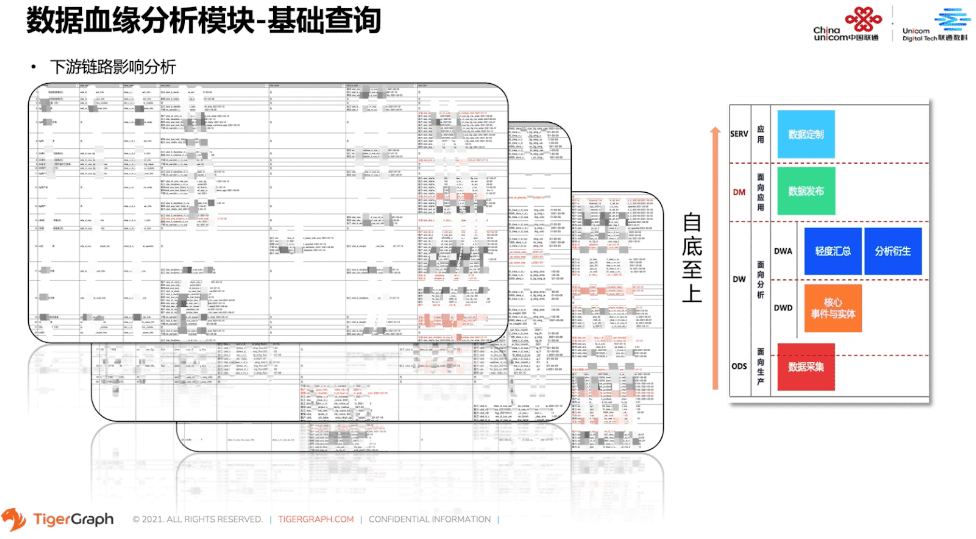
小功能可以解决大问题。我们在数仓建设的过程中往往需要做数据加工流程的迭代开发。数据公司生产加工链路庞大且繁杂。每一个细微的改动可谓是牵一发而动全身,都会产生影响辐射效应。特别是在数据孤岛下陷,冗余流程的优化,新老加工流程的替换等场景下,如果我们做任何的修改,结果都会对各个业务线产生影响。那么对于下游表的业务影响范围来说,相关方的确定分析影响力也尤为重要。
数据血缘下游表链路查询就完美的契合了这个场景的需求。在每个数据的加工流程优化过程中,我们都要从贴源层到应用层,做自底而上的影响力分析。对于每个数据流、每条业务线,都要达到全链路监控、及时反馈、加工溯源等功能。 就在下游表链路分析影响的助力下,保障了我们的数仓完成了多轮的迭代。
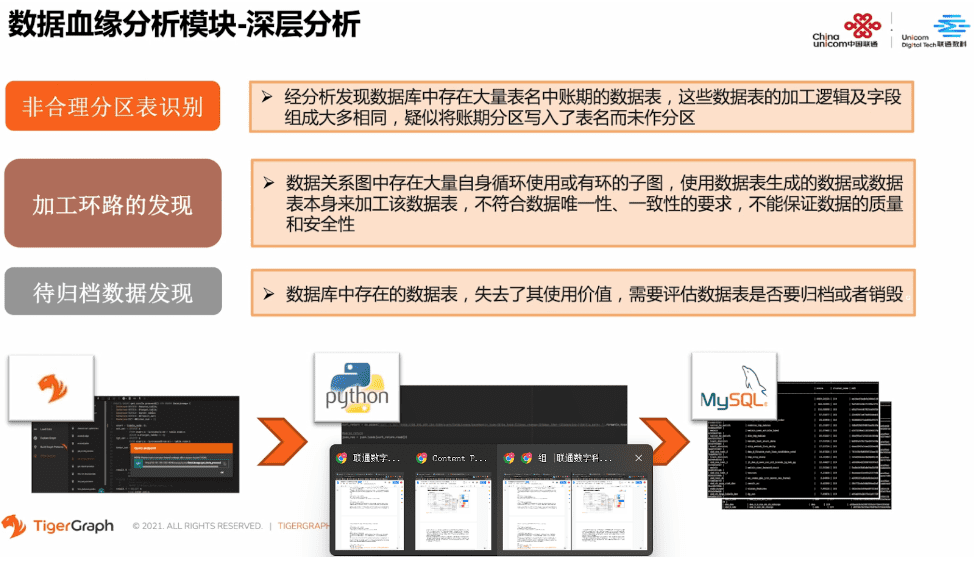
对于血缘分析功能中的血缘深层分析,TigerGraph自带的GraphStudio就不能满足我们的需求了。完成图计算的各个分析算法的功能后,需要用Python调用图计算API的方式,再将分析结果加工为Pandas的DataFrame,然后在MySQL数据库中做持久化保存。
那现在我们就来看一下数据血缘深层分析都包含哪些部分。
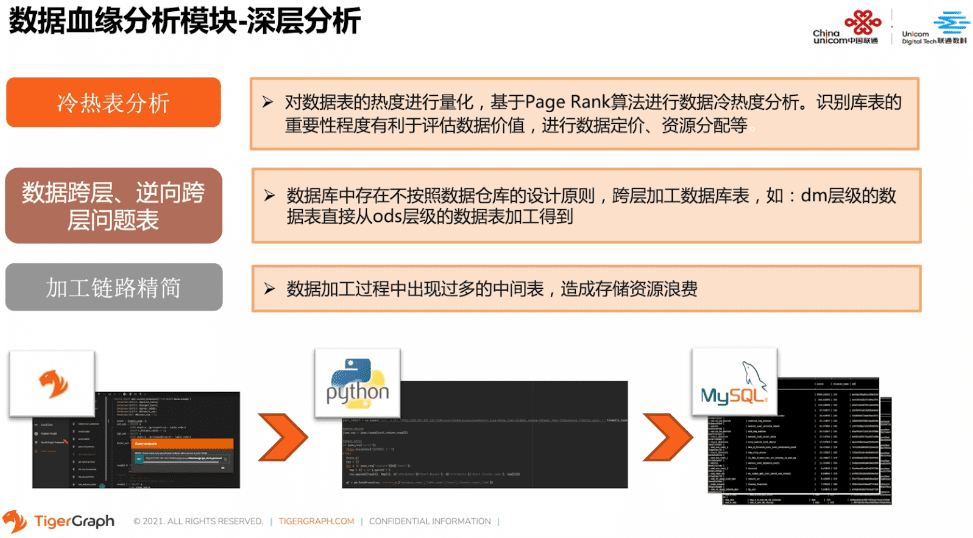

以上血缘分析的结果就可以应用于自动化分析报告模块。以Python实现的模块,从MySQL取到血缘分析结果的数据表,然后在此基础上结合一定的数理统计分析,将结果以图表的形式结合数据报告的模板文档,自动化地生成分析报告,为数据管理人员和数据开发人员提供有力的支持。
以上,就是整个数据血缘系统的所有内容。
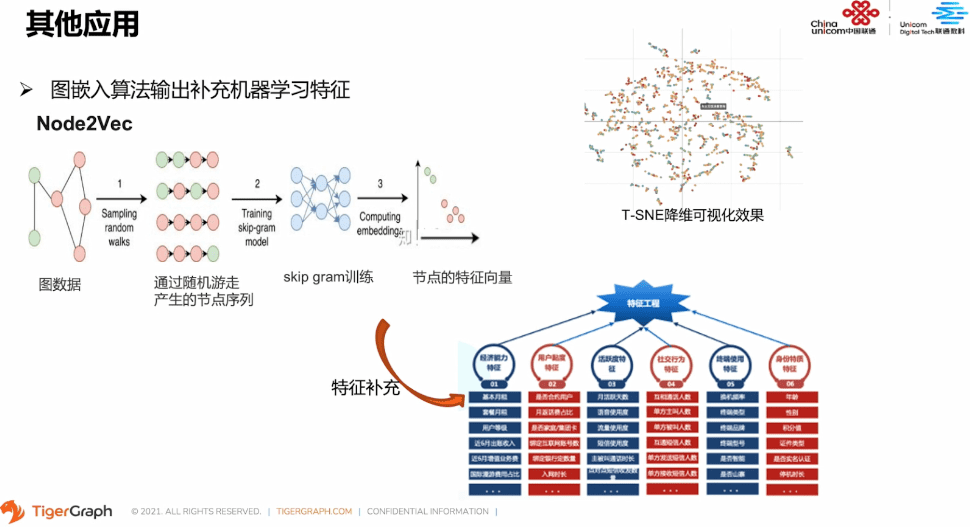
当然,我们在图应用的道路上肯定不止刚才分享的案例。因为时间关系,这里再简单介绍一个图嵌入算法的案例。在App特征提取的场景下,我们构建了用户使用App的关系网络图,用图嵌入算法将用户使用App这种图结构的信息呢,嵌入到第一位的向量中,选取的图嵌入方式是Node2Vec。通过在图上随机游走采样,生成采样序列之后,用Spark的MLlib包中自带的Word2Vec的方法以处理文本词嵌入的方式计算,得到最后的特征向量,最后结果用于补充原有的机器学习模型的特征。
模型的评估指标都有明显的提升。左上角的图,是通过图嵌入算法计算得到的所有App向量的结果,再经过T-SNE降维可视化的效果。我们通过肉眼就可以看出,最后的特征向量在二维空间上具有明显的聚集效应,也就是说最后的图嵌入效果非常好。
以上,就是我今天的分享。希望更多的朋友、专家加入到图应用的行列中,一起探讨学习、交流进步、赋能行业。
Anna Veronika Dorogus
Machine Learning Expert
Anna Veronika Dorogush graduated from Lomonosov Moscow State University and Yandex School of Data Analysis. She used to work at ABBYY, Yandex, Microsoft and Google on Machine Learning infrastructure and Machine Learning frameworks. In 2017 she published the open-source library CatBoost, which is now one of top-3 most popular Gradient Boosting libraries, and the top 7-th most used Machine Learning framework in the world according to Kaggle 2021 review.