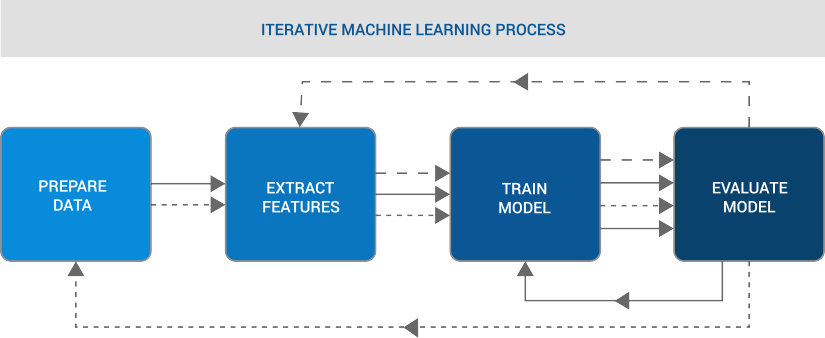
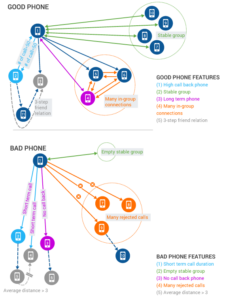
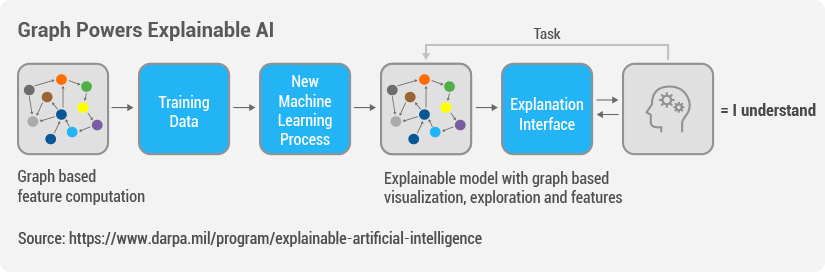
由于各种企业系统和工具数量的激增,造成客户数据具有多个不同版本。每个面向客户和后台的系统(包括 CMS、ERP、营销自动化、CRM、网站和存储系统)都包含一部分客户数据。这包括交易数据(如订单、保单、支付、索赔),还包括渠道交互数据(如客户服务电话、网站和实体店到访)。
所有这些数据存在大量重复和不一致,因此超过 41% 的 B2B 营销者将这视为他们的最大挑战。在流程中及早发现并解决这些问题,是更好、性价比更高的解决方式,如 1-10-100 规则所示:在输入数据时验证数据需要1美元,数据清洗需要 10 美元,未进行清洗的数据进行数据分析可能需要100美元的成本。
现在,企业比以往任何时候都更希望创建一个MDM主数据管理系统,并从中存储交易、交互和主数据,用于有效开展营销活动并增加收入。